主题
快速开始
资源需求
| 资源 | 数量 |
|---|---|
| RTX 4090 24GB | 1 |
| 数据盘 | 50GB |
使用步骤
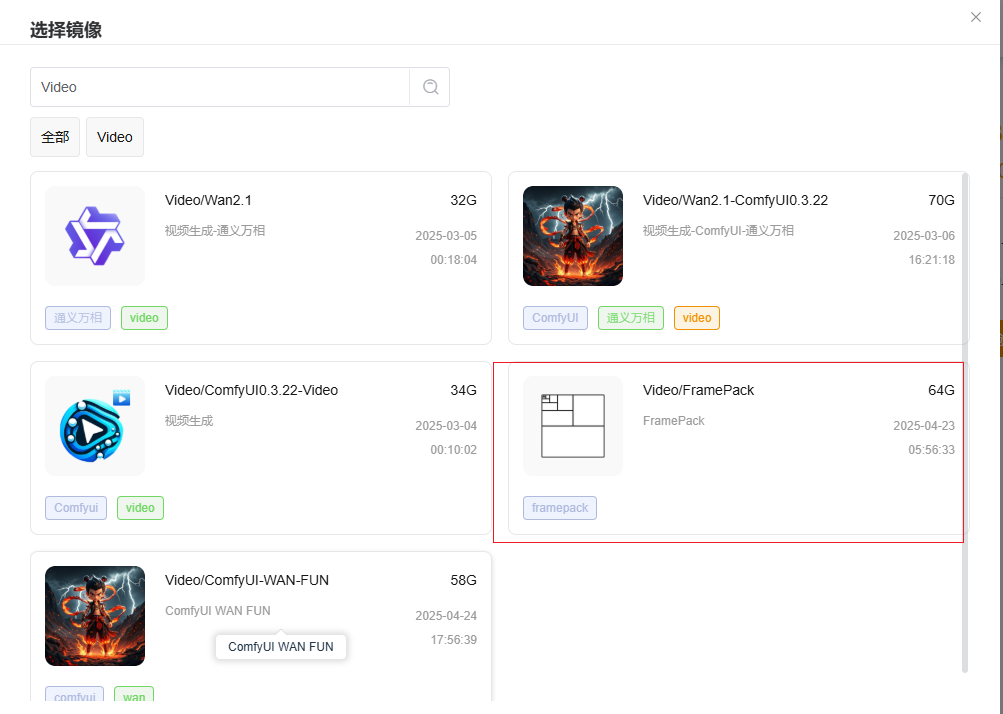
0. 创建镜像
您可以参考平台的快速开始来创建镜像。 在选择镜像时,选择Fooocus:
1. 启动WebUI
开机后约10秒webui启动完成,点击实例的webui按钮即可启动webui。启动WebUI的教程请参考这篇文档↗
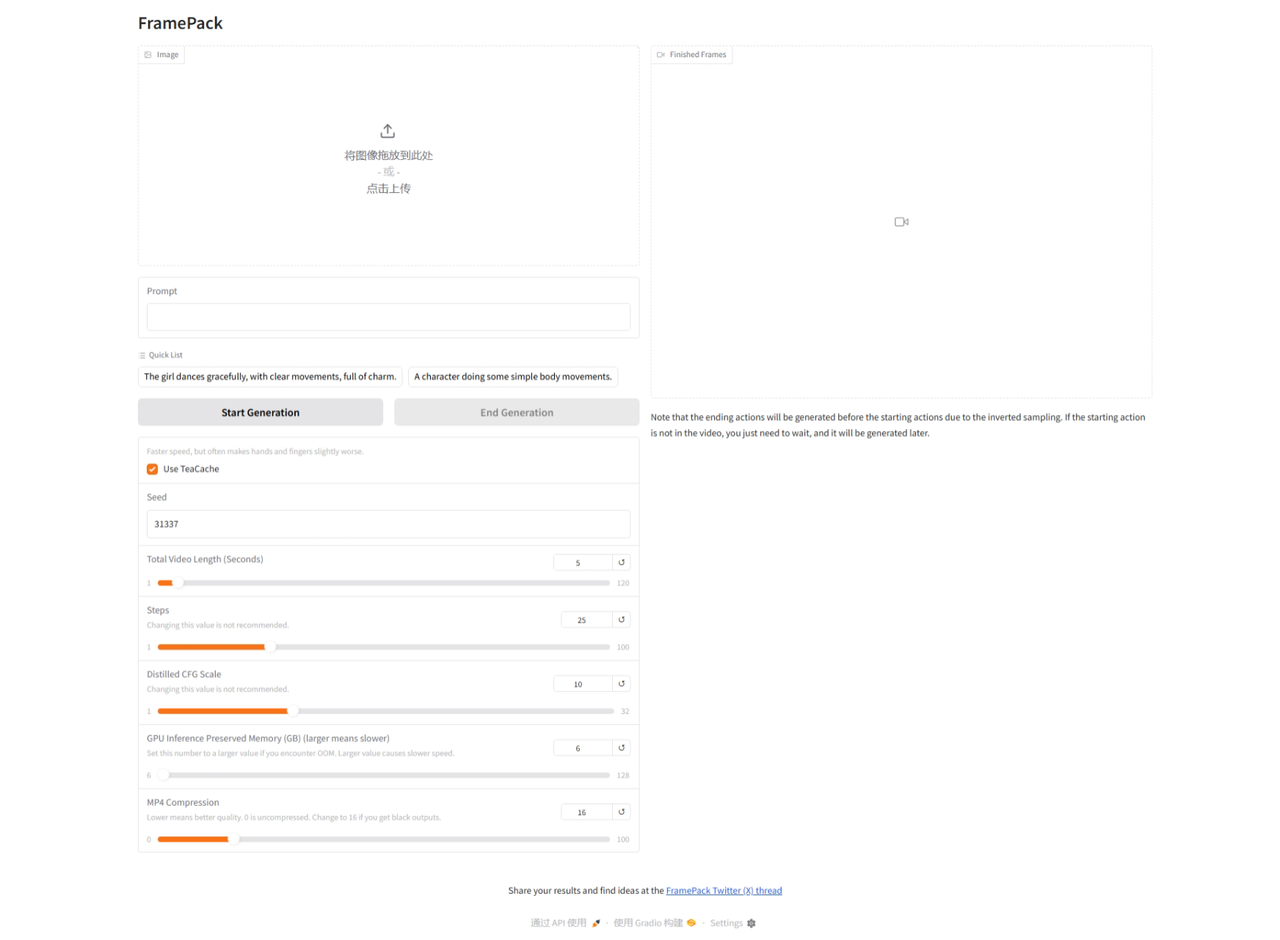
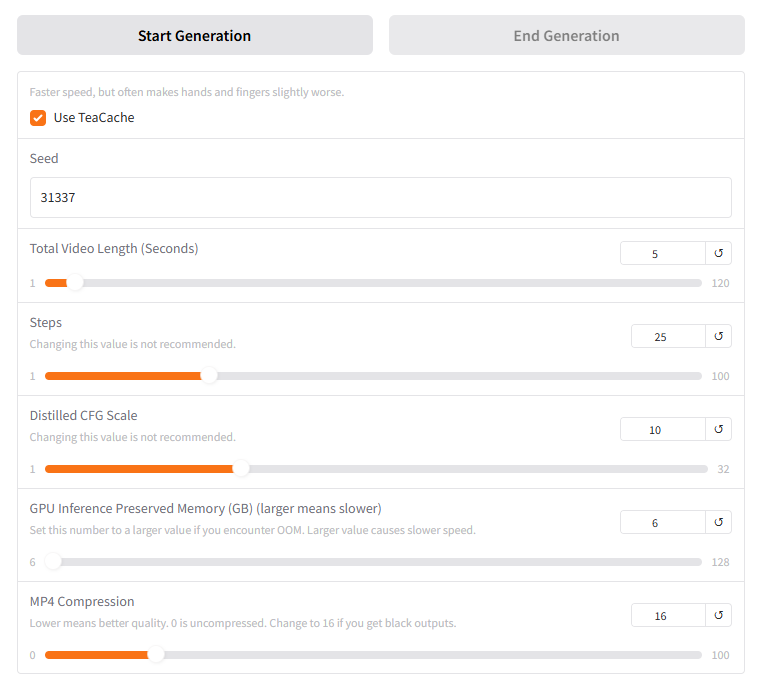
上传图片并输入提示词,然后根据需要调整以下参数:
2. 生成视频
点击“start generation”按钮生成视频,视频是逐秒生成的,右侧界面可以看到生成视频的过程。生成视频所需的时间取决于视频的长度,根据生成每秒视频的时间可以大致推断出生成完整视频的时间。
TeaCache
不使用“TeaCache”,生成一分钟视频大约需要两个半小时。
完整视频和分段视频文件都默认保存在/opt/FramePack/outputs文件夹下。
3. 提示词生成
官方提供了一段提示词可以使视觉多模态大模型根据图片生成视频提示词:
txt
You are an assistant that writes short, motion-focused prompts for animating images.
When the user sends an image, respond with a single, concise prompt describing visual motion (such as human activity, moving objects, or camera movements). Focus only on how the scene could come alive and become dynamic using brief phrases.
Larger and more dynamic motions (like dancing, jumping, running, etc.) are preferred over smaller or more subtle ones (like standing still, sitting, etc.).
Describe subject, then motion, then other things. For example: "The girl dances gracefully, with clear movements, full of charm."
If there is something that can dance (like a man, girl, robot, etc.), then prefer to describe it as dancing.
Stay in a loop: one image in, one motion prompt out. Do not explain, ask questions, or generate multiple options.镜像默认安装了ollama,用户可以使用ollama手动下载支持视觉多模态的大模型,如gemma3(镜像中ollama默认没有下载任何模型),然后使用大模型生成提示词。
sh
# 启动ollama
ollama serve
ollama pull gemma3:27b镜像中也内置了名为tag.py的脚本,在默认的app环境下,用户只需要输入以下命令即可生成提示词
sh
# model是参数必需的,可以是其他模型名称
# image参数是实例上本地图片文件的路径,不能是网络图片的url
# 可以设置'--base_url'和'--api_key'来使用非ollama的模型服务
python /opt/tag.py --model gemma3:27b --image /path/to/image
> The students dance energetically, with synchronized steps, in a cheerful mood.关于显存
由于ollama使用模型进行推理也需要占用显存,所以如果没有使用多卡,最好不要同时启动webui和ollama的模型。 如果您需要同时使用,您可以使用多卡来提升性能; 或者单独启动一个ollama实例,将提示词生成和文生视频工作分开。